
⭐️ Highlights
Enhanced Agent Tracing and Async Support
Haystack’s
Agent got several improvements!
Agent Tracing
Agent tracing now provides deeper visibility into the agent’s execution. For every call, the inputs and outputs of the ChatGenerator and ToolInvoker are captured and logged using dedicated child spans. This makes it easier to debug, monitor, and analyze how an agent operates step-by-step.
Below is an example of what the trace looks like in Langfuse:
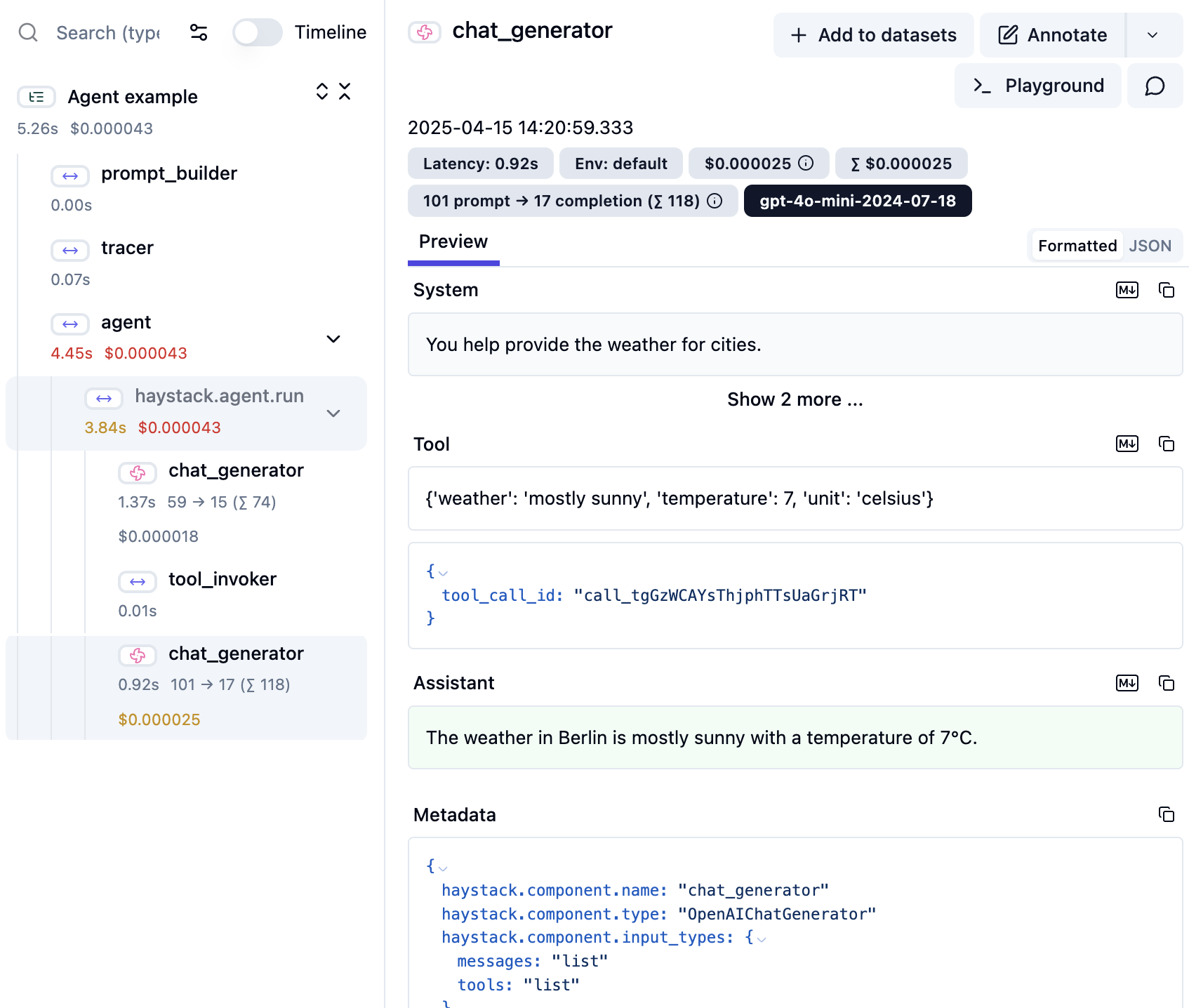
# pip install langfuse-haystack
from haystack_integrations.components.connectors.langfuse.langfuse_connector import LangfuseConnector
from haystack.components.agents import Agent
from haystack.components.generators.chat import OpenAIChatGenerator
tracer = LangfuseConnector("My Haystack Agent")
agent = Agent(
system_prompt="You help provide the weather for cities"
chat_generator=OpenAIChatGenerator(),
tools=[weather_tool],
)
Async Support
Additionally, there’s a new run_async method to enable built-in async support for Agent. Just use run_async instead of the run method. Here’s an example of an async web search agent:
# set `SERPERDEV_API_KEY` and `OPENAI_API_KEY` as env variables
from haystack.components.agents import Agent
from haystack.components.generators.chat import OpenAIChatGenerator
from haystack.components.websearch import SerperDevWebSearch
from haystack.dataclasses import ChatMessage
from haystack.tools.component_tool import ComponentTool
web_tool = ComponentTool(component=SerperDevWebSearch())
web_search_agent = Agent(
chat_generator=OpenAIChatGenerator(),
tools=[web_tool],
)
result = await web_search_agent.run_async(
messages=[ChatMessage.from_user("Find information about Haystack by deepset")]
)
New Toolset for Enhanced Tool Management
The new
Toolset groups multiple Tool instances into a single manageable unit. It simplifies the passing of tools to components like ChatGenerator, ToolInvoker, or Agent, and supports filtering, serialization, and reuse.
Check out the
MCPToolset for dynamic tool discovery from an MCP server.
from haystack.tools import Toolset
from haystack.components.agents import Agent
from haystack.components.generators.chat import OpenAIChatGenerator
math_toolset = Toolset([tool_one, tool_two, ...])
agent = Agent(
chat_generator=OpenAIChatGenerator(model="gpt-4o-mini"),
tools=math_toolset
)
@super_component decorator and new ready-made SuperComponents
Creating a custom
SuperComponents just got even simpler. Now, all you need to do is define a class with a pipeline attribute and decorate it with @super_component. Haystack takes care of the rest!
Here’s an example of building a custom HybridRetriever using the @super_component decorator:
# pip install haystack-ai datasets "sentence-transformers>=3.0.0"
from haystack import Document, Pipeline, super_component
from haystack.components.joiners import DocumentJoiner
from haystack.components.embedders import SentenceTransformersTextEmbedder
from haystack.components.retrievers import InMemoryBM25Retriever, InMemoryEmbeddingRetriever
from haystack.document_stores.in_memory import InMemoryDocumentStore
from datasets import load_dataset
@super_component
class HybridRetriever:
def __init__(self, document_store: InMemoryDocumentStore, embedder_model: str = "BAAI/bge-small-en-v1.5"):
embedding_retriever = InMemoryEmbeddingRetriever(document_store)
bm25_retriever = InMemoryBM25Retriever(document_store)
text_embedder = SentenceTransformersTextEmbedder(embedder_model)
document_joiner = DocumentJoiner(join_mode="reciprocal_rank_fusion")
self.pipeline = Pipeline()
self.pipeline.add_component("text_embedder", text_embedder)
self.pipeline.add_component("embedding_retriever", embedding_retriever)
self.pipeline.add_component("bm25_retriever", bm25_retriever)
self.pipeline.add_component("document_joiner", document_joiner)
self.pipeline.connect("text_embedder", "embedding_retriever")
self.pipeline.connect("bm25_retriever", "document_joiner")
self.pipeline.connect("embedding_retriever", "document_joiner")
dataset = load_dataset("HaystackBot/medrag-pubmed-chunk-with-embeddings", split="train")
docs = [Document(content=doc["contents"], embedding=doc["embedding"]) for doc in dataset]
document_store = InMemoryDocumentStore()
document_store.write_documents(docs)
query = "What treatments are available for chronic bronchitis?"
result = HybridRetriever(document_store).run(text=query, query=query)
print(result)
New ready-made SuperComponents: MultiFileConverter, DocumentPreprocessor
There are also two ready-made SuperComponents,
MultiFileConverter and
DocumentPreprocessor, that encapsulate widely used common logic for indexing pipelines.
📚 Learn more about SuperComponents and get the full code example in the
Tutorial: Creating Custom SuperComponents
⬆️ Upgrade Notes
- The deprecated
api,api_key, andapi_paramsparameters forLLMEvaluator,ContextRelevanceEvaluator, andFaithfulnessEvaluatorhave been removed. By default, these components will continue to use OpenAI in JSON mode. To customize the LLM, use thechat_generatorparameter with aChatGeneratorinstance configured to return a response in JSON format. For example:
chat_generator=OpenAIChatGenerator(generation_kwargs={"response_format": {"type": "json_object"}})
- The deprecated
generator_apiandgenerator_api_paramsinitialization parameters ofLLMMetadataExtractorand theLLMProviderenum have been removed. Usechat_generatorinstead to configure the underlying LLM. In order for the component to work, the LLM should be configured to return a JSON object. For example, if using OpenAI, you should initialize theLLMMetadataExtractorwith
chat_generator=OpenAIChatGenerator(generation_kwargs={"response_format": {"type": "json_object"}})
🚀 New Features
- Add run_async for
OpenAITextEmbedder. - Add
run_asyncmethod toHuggingFaceAPIDocumentEmbedder. This method enriches Documents with embeddings. It supports the same parameters as therunmethod. It returns a coroutine that can be awaited. - Support custom HTTP client configuration via
http_client_kwargs(proxy, SSL) for:AzureOpenAIGenerator,OpenAIGeneratorandDALLEImageGeneratorOpenAIDocumentEmbedderandOpenAITextEmbedderRemoteWhisperTranscriber
OpenAIChatGeneratorandAzureOpenAIChatGeneratornow support custom HTTP client config viahttp_client_kwargs, enabling proxy and SSL setup.- Introduced the Toolset class, allowing for the grouping and management of related tool functionalities. This new abstraction supports dynamic tool loading and registration.
- We have added internal tracing support to Agent. It is now possible to track the internal loops within the agent by viewing the inputs and outputs each time the ChatGenerator and ToolInvoker is called.
- The
HuggingFaceAPITextEmbeddernow also has support for a run() method in an asynchronous way, i.e., run_async. - Add a run_async to the Agent, which calls the run_async of the underlying ChatGenerator if available.
- SuperComponents now support mapping nonleaf pipelines outputs to the SuperComponents output when specifying them in
output_mapping. AzureOpenAITextEmbedderandAzureOpenAIDocumentEmbeddernow support custom HTTP client config viahttp_client_kwargs, enabling proxy and SSL setup.- The
AzureOpenAIDocumentEmbeddercomponent now inherits from theOpenAIDocumentEmbeddercomponent, enabling asynchronous usage. - The
AzureOpenAITextEmbeddercomponent now inherits from theOpenAITextEmbeddercomponent, enabling asynchronous usage. - Added async support to the
OpenAIDocumentEmbeddercomponent. - Agent now supports a List of Tools or a Toolset as input.
⚡️ Enhancement Notes
- Added
component_nameandcomponent_typeattributes toPipelineRuntimeError.- Moved error message creation to within
PipelineRuntimeError - Created a new subclass of PipelineRuntimeError called PipelineComponentsBlockedError for the specific case where the pipeline cannot run since no components are unblocked.
- Moved error message creation to within
- The
ChatGeneratorProtocol no longer requiresto_dictandfrom_dictmethods.
⚠️ Deprecation Notes
- The utility function
deserialize_tools_inplacehas been deprecated and will be removed in Haystack 2.14.0. Usedeserialize_tools_or_toolset_inplaceinstead.
🐛 Bug Fixes
OpenAITextEmbedderno longer replaces newlines with spaces in the text to embed. This was only required for the discontinued v1 embedding models.OpenAIDocumentEmbedderandAzureOpenAIDocumentEmbedderno longer replace newlines with spaces in the text to embed. This was only required for the discontinued v1 embedding models.- Fix
ChatMessage.from_dictto handle cases where optional fields likenameandmetaare missing. - Make Document’s first-level fields to take precedence over meta fields when flattening the dictionary representation.
- In Agent we make sure state_schema is always initialized to have ‘messages’. Previously this was only happening at run time which is why pipeline.connect failed because output types are set at init time. Now the Agent correctly sets everything in state_schema (including messages by default) at init time. Now, when you call an Agent without tools, it acts like a ChatGenerator, which means it returns a ChatMessage based on user input.
- In
AsyncPipeline, the span tag name is updated fromhasytack.component.outputstohaystack.component.output. This matches the tag name used in Pipeline and is the tag name expected by our tracers. - The batch_size parameter has now been added to to_dict function of TransformersSimilarityRanker. This means serialization of batch_size now works as expected.